27 Apr

Last updated: April 27, 2026
Quick Answer
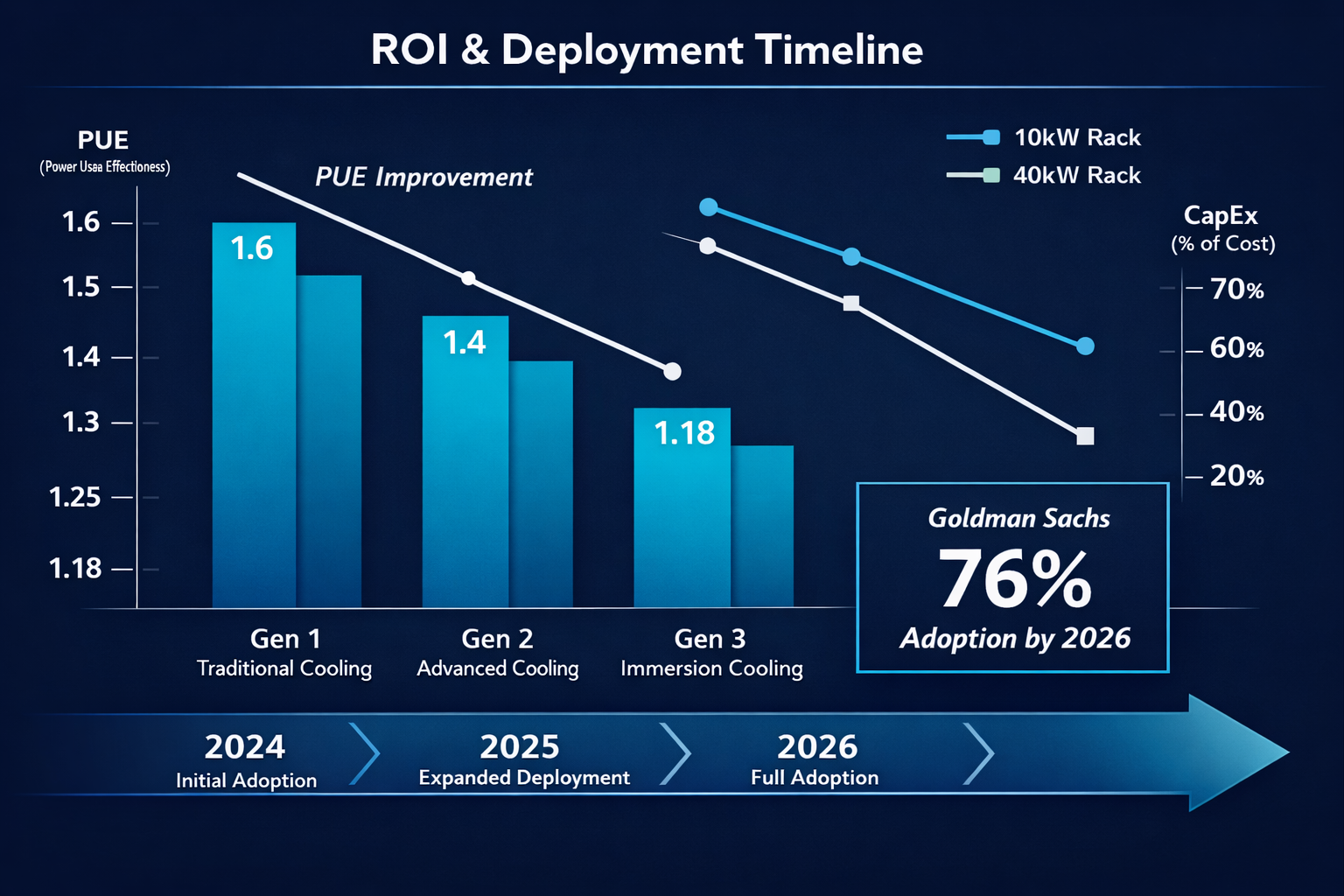
Liquid cooling for hyperscale AI racks has moved well past direct-to-chip cold plates. In 2026, two-phase immersion cooling, rear-door heat exchangers, and intelligent CDU (coolant distribution unit) architectures are handling rack densities above 40 kW that air cooling simply cannot manage. Goldman Sachs forecasts that 76% of AI servers will use liquid cooling by end of 2026, up from just 15% in 2024 [1].
Key Takeaways 🔑
- Rack density has jumped from an average of 6.1 kW nine years ago to 16 kW today, with AI workloads now demanding 30–40 kW or more per rack, breaking air cooling’s thermal ceiling [5]
- Liquid cooling is 25x more efficient than air-based systems, with heat transfer capability up to 3,500 times more effective depending on water volume, per Jefferies’ September 2024 research [1]
- Two-phase immersion cooling is emerging as the leading architecture for next-generation AI racks, offering 50%+ efficiency gains over direct-to-chip approaches for the densest GPU workloads [6]
- ASUS achieved a PUE of 1.18 using direct liquid cooling, well below the industry average, and validated performance with 248 No. 1 MLPerf™ results [2]
- Liquid cooling becomes economically advantageous above 40 kW, with Schneider Electric modeling showing cooling costs consuming 21% of capex at that density for liquid-cooled racks [1]
- 19% of data center operators currently use liquid cooling, with many more planning adoption within two years, signaling rapid mainstream uptake [5]
- Intelligent cooling infrastructure now includes predictive maintenance, dynamic workload migration, and real-time thermal headroom adjustments that treat cooling as an active compute layer [4]
- Deployment timelines matter: retrofitting an existing air-cooled facility for immersion cooling typically takes 12–18 months, while greenfield liquid-native builds can be operational in 8–12 months
Why Is Air Cooling Failing AI Data Centers in 2026?
Air cooling is hitting a hard physical limit: it cannot remove heat fast enough from racks running modern AI accelerators at 30–100+ kW. The thermal math simply doesn’t work at scale.
Average rack density has grown from 6.1 kW nine years ago to 16 kW today. AI workloads, particularly those running NVIDIA Blackwell and Vera Rubin-class GPUs, now demand 30–40 kW per rack or higher [5]. A standard computer room air conditioning (CRAC) unit moves heat by blowing air across components, but air has low thermal conductivity. At densities above roughly 20 kW per rack, hot aisle temperatures spike, cooling uniformity collapses, and hardware throttles or fails.
The core problem breaks down into three areas:
- Thermal conductivity gap: Water conducts heat roughly 25 times better than air [1]. At 40 kW rack densities, that gap becomes operationally critical.
- Space inefficiency: Air cooling requires wide hot/cold aisle spacing, raised floors, and overhead plenum space. Liquid cooling eliminates most of this overhead.
- Energy waste: Traditional air-cooled data centers often run at a PUE (power usage effectiveness) of 1.4–1.6, meaning 40–60% of energy consumed goes to cooling rather than compute.
“Liquid cooling is no longer a premium option for specialized workloads. At 40 kW and above, it’s the only engineering-sound choice.” — ByteBridge Liquid Cooling Analysis, 2026 [4]
Common mistake: Many operators assume they can solve density problems by adding more CRAC units. Beyond roughly 20–25 kW per rack, adding air cooling capacity yields diminishing returns and increases both capex and floor space requirements without solving the fundamental thermal transfer problem.
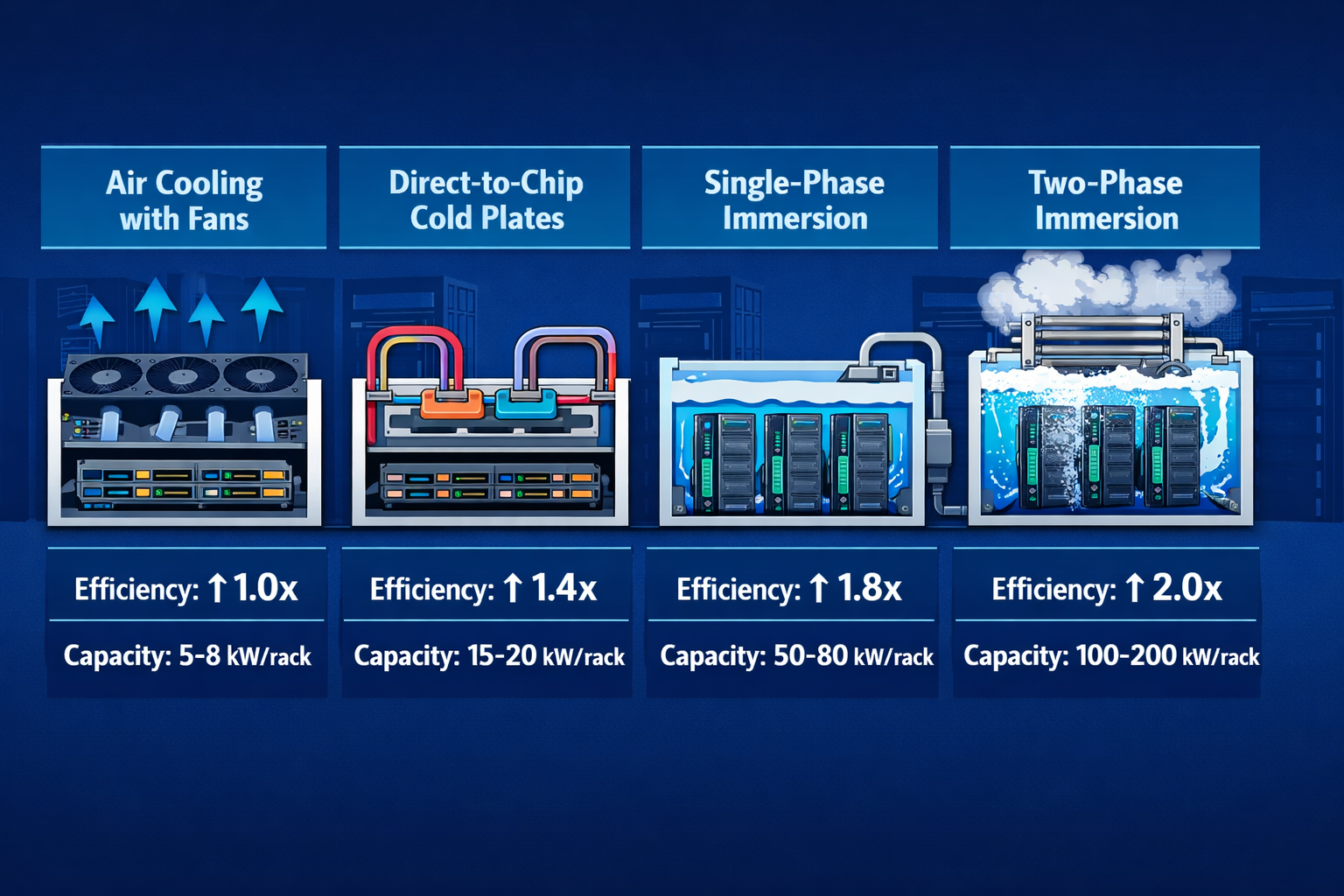
What Are the Main Liquid Cooling Architectures in 2026?
The liquid cooling landscape in 2026 covers four distinct architectures, each suited to different rack densities, retrofit scenarios, and budget profiles. Choosing the wrong one is an expensive mistake.
| Architecture | Best Rack Density | PUE Range | Retrofit Difficulty | Relative Cost |
|---|---|---|---|---|
| Rear-Door Heat Exchanger (RDHx) | 10–25 kW | 1.3–1.45 | Low | $ |
| Direct-to-Chip (D2C) Cold Plate | 20–60 kW | 1.15–1.25 | Medium | $$ |
| Single-Phase Immersion | 40–100 kW | 1.03–1.15 | High | $$$ |
| Two-Phase Immersion | 50–120+ kW | 1.02–1.10 | High | $$$$ |
Rear-Door Heat Exchangers (RDHx)
RDHx units replace a standard rack door with a water-cooled panel that captures heat as it exits the server. This is the easiest retrofit path because it requires no changes to the servers themselves. It works well up to about 25 kW per rack and integrates with existing chilled water infrastructure. The tradeoff: it doesn’t cool individual chips directly, so hotspot management is limited.
Choose RDHx if: Your existing racks run below 25 kW, you need a fast retrofit (weeks, not months), and your facility already has chilled water distribution.
Direct-to-Chip (D2C) Cold Plates
Cold plates attach directly to CPUs and GPUs, circulating coolant across the chip surface. This is the architecture ASUS deployed for NVIDIA Vera Rubin NVL72-based AI data centers in February 2026, achieving a PUE of 1.18 [2]. D2C is currently the most common advanced liquid cooling method in hyperscale AI deployments.
Choose D2C if: Your racks run 20–60 kW, you’re working with standard server form factors, and you want proven technology with a growing vendor ecosystem.
Single-Phase Immersion Cooling
Servers are fully submerged in a dielectric fluid that remains liquid throughout the cooling cycle. Heat is transferred from components directly to the fluid, which then cycles through a heat exchanger. This handles very high densities and eliminates fans entirely, but requires purpose-built tanks and significant facility changes.
Two-Phase Immersion Cooling: The 2026 Breakthrough
Two-phase immersion is where the most significant liquid cooling breakthroughs in 2026 are happening. Servers submerge in a low-boiling-point dielectric fluid. The fluid boils at the chip surface, absorbing large amounts of latent heat, then condenses on a water-cooled coil above and drips back down. This phase-change cycle is extraordinarily efficient.
The CEO of Accelsius, a two-phase cooling specialist, notes that these systems can plug into existing water-cooled data centers, reducing both capital and operational expenditures compared to building entirely new infrastructure [6]. For racks running NVIDIA Blackwell or Vera Rubin GPUs at 80–120 kW, two-phase immersion is increasingly the only architecture that doesn’t require thermal throttling.
How Do Liquid Cooling Breakthroughs Beyond Direct-to-Chip Change the ROI Equation?
Liquid cooling’s ROI depends heavily on rack density. Below 20 kW, the economics favor air cooling. Above 40 kW, liquid cooling pays back faster than most operators expect.
Schneider Electric’s modeling shows that at 40 kW rack density, cooling consumes 21% of capex in a liquid-cooled deployment, compared to 10% for a 10 kW air-cooled rack [1]. That sounds like liquid cooling costs more, and upfront it does. But the calculation shifts when you factor in:
Energy savings: Liquid cooling delivers 15% energy efficiency gains and meaningfully reduced cooling costs versus air systems [1]. A data center running at PUE 1.18 (as ASUS demonstrated) versus PUE 1.5 saves roughly 21% of total facility power on cooling alone.
Hardware lifespan: Lower operating temperatures extend GPU and CPU lifespan. Components running at 20–30°C below their thermal design point degrade more slowly, reducing hardware replacement cycles.
Compute density: Liquid-cooled racks pack more compute into less floor space. For hyperscale operators paying $1,000–$3,000+ per square foot for data center space, density gains translate directly to capex savings on facility construction.
A simplified ROI framework for operators:
- Calculate current PUE and multiply by annual power cost to find total cooling overhead
- Estimate target PUE for the chosen liquid cooling architecture (1.10–1.20 for D2C or immersion)
- Subtract to find annual energy savings
- Add hardware lifespan extension value (estimate 10–15% reduction in annual hardware refresh cost)
- Divide total capex premium for liquid cooling by annual combined savings to get payback period
For most hyperscale AI deployments above 40 kW, payback periods of 2–4 years are achievable. At 80+ kW densities with two-phase immersion, payback can compress to 18–30 months because the alternative (air cooling) simply doesn’t work, meaning the comparison is liquid cooling versus building a larger, less dense facility.

What Does the 2026 Vendor Ecosystem Look Like for Hyperscale Liquid Cooling?
The vendor landscape has matured significantly. In 2026, operators no longer need to stitch together bespoke solutions. Integrated partnerships and validated reference architectures are now available.
ASUS announced strategic liquid cooling solutions in February 2026 specifically designed for NVIDIA Vera Rubin NVL72-based AI data centers, covering D2C, in-row CDU, and hybrid cooling architectures [2]. Critically, ASUS established global partnerships with Schneider Electric, Vertiv, Auras Technology, and Cooler Master to deliver end-to-end solutions at hyperscale [2].
Key vendor categories and what they provide:
- OEM server vendors (ASUS, Supermicro, HPE, Dell): Liquid-ready server platforms with integrated cold plate mounting points
- CDU manufacturers (Vertiv, Auras Technology, Asetek): Coolant distribution units that manage flow rates, temperatures, and leak detection
- Facility infrastructure (Schneider Electric, Eaton): Power distribution and facility integration for liquid cooling loops
- Immersion specialists (Accelsius, GRC, LiquidStack): Purpose-built tanks, dielectric fluids, and two-phase systems
- Chip vendors (NVIDIA, AMD, Intel): GPU and CPU designs increasingly optimized for liquid cooling attachment points
Validation matters: ASUS validated its liquid cooling performance with 2,156 industry-leading No. 1 SPEC CPU® records and 248 No. 1 MLPerf™ results [2]. When evaluating vendors, ask for third-party benchmark validation at the target rack density, not just theoretical specifications.
Edge case to watch: Not all dielectric fluids are compatible with all server hardware. Some fluids degrade certain plastics, adhesives, or connector materials over time. Always verify fluid compatibility with server OEM specifications before committing to an immersion deployment.
How Is Intelligent Cooling Changing Hyperscale AI Operations?
Liquid cooling in 2026 is not just a passive thermal management system. It has become an active, intelligent infrastructure layer that directly affects AI workload performance.
Modern liquid cooling platforms now include [4]:
- Predictive maintenance: Sensors monitor pump vibration, flow rates, and fluid chemistry to identify pump wear or micro-leaks weeks before they cause failures
- Dynamic workload migration: The cooling system communicates with the orchestration layer to migrate AI training jobs away from thermally constrained zones before throttling occurs
- Real-time thermal headroom management: AI training batch sizes and clock frequencies adjust automatically based on available cooling capacity, maximizing GPU utilization without thermal risk
- Digital twin integration: Facility operators run virtual models of their cooling infrastructure to simulate the thermal impact of adding new racks before physical deployment
This intelligence layer changes the operational model for hyperscale AI. Instead of provisioning cooling headroom conservatively (and wasting it most of the time), operators can run closer to thermal limits with confidence because the system self-regulates.
Practical deployment consideration: Intelligent cooling systems require integration with the data center infrastructure management (DCIM) platform and the AI orchestration layer (Kubernetes, Slurm, or proprietary schedulers). Budget 3–6 months for integration and tuning when deploying intelligent liquid cooling alongside existing AI workload management systems.
What Are the Deployment Timelines and Common Mistakes for Liquid Cooling Rollouts?
Deployment timelines vary significantly by architecture and whether the facility is a retrofit or greenfield build.
Typical timelines:
| Scenario | Architecture | Timeline |
|---|---|---|
| Retrofit existing air-cooled facility | RDHx | 4–8 weeks per row |
| Retrofit existing facility | D2C cold plate | 3–6 months |
| Retrofit for immersion | Single or two-phase | 12–18 months |
| Greenfield liquid-native build | Any | 8–14 months |
Most common deployment mistakes:
Underestimating facility water infrastructure requirements. D2C and immersion systems need chilled water supply lines, leak detection, and secondary containment. Many operators discover their existing chilled water plant lacks the capacity or pressure for high-density liquid cooling loops.
Skipping pilot deployments. Moving directly from air cooling to full-rack immersion at scale without a 5–10 rack pilot is high risk. Run a pilot for 60–90 days to validate fluid compatibility, integration with DCIM, and maintenance procedures.
Ignoring maintenance access design. Immersion tanks require lifting servers out of fluid for maintenance. Overhead clearance, drain systems, and cleaning stations need to be designed into the facility layout from the start.
Treating cooling and compute procurement separately. Liquid-ready servers, CDUs, and facility infrastructure need to be specified together. Buying servers first and cooling equipment second often results in compatibility gaps.
Underestimating fluid management costs. Dielectric fluids for immersion cooling require periodic testing, top-off, and eventual replacement. Factor in an ongoing fluid management budget of roughly 1–3% of fluid volume annually.
Liquid Cooling Breakthroughs: Beyond Direct-to-Chip — Adoption Data and What Comes Next
The adoption curve for liquid cooling breakthroughs beyond direct-to-chip is accelerating faster than most infrastructure forecasts predicted two years ago.
Goldman Sachs forecasts liquid-cooled AI server adoption will reach 76% in 2026, up from 54% in 2025 and just 15% in 2024 [1]. Currently, 19% of data center operators use liquid cooling broadly, with many more planning adoption within two years [5]. The gap between those two numbers reflects the hyperscale AI segment pulling far ahead of the broader enterprise market.
What’s driving the acceleration:
- NVIDIA’s Vera Rubin NVL72 platform, designed for liquid cooling from the ground up, is pushing hyperscale buyers toward liquid-native infrastructure
- Power utility constraints in major data center markets (Northern Virginia, Dublin, Singapore, Tokyo) are making PUE improvements economically mandatory, not optional
- Cooling-as-a-service models from vendors like Vertiv and Schneider Electric are reducing the upfront capex barrier for mid-tier operators
What comes next (2026–2028 outlook):
- Chip-embedded microfluidics: NVIDIA and AMD are actively developing GPU packages with integrated microfluidic channels, eliminating the cold plate attachment step entirely
- Waste heat reuse: Two-phase immersion systems operating at higher fluid temperatures (40–60°C) can supply waste heat to district heating networks or on-site absorption chillers, turning a cost center into a partial revenue stream
- Standardization: ASHRAE TC 9.9 and the Open Compute Project are finalizing liquid cooling standards that will reduce integration complexity and vendor lock-in
FAQ: Liquid Cooling for Hyperscale AI Racks
Q: What rack density requires liquid cooling? Liquid cooling becomes practically necessary above 30–40 kW per rack. Air cooling can technically function up to about 25 kW with aggressive airflow management, but efficiency and reliability degrade significantly above that threshold.
Q: Is two-phase immersion cooling safe for standard server hardware? Most modern server hardware is compatible with engineered dielectric fluids used in two-phase immersion, but compatibility must be verified per server model. Connectors, labels, and certain plastics can degrade with incompatible fluids. Always check OEM specifications.
Q: What PUE can liquid cooling achieve? D2C cold plate systems can achieve PUE of 1.15–1.25. Single-phase and two-phase immersion systems can reach PUE of 1.02–1.10 in optimized deployments. ASUS demonstrated a PUE of 1.18 with direct liquid cooling in a production AI environment [2].
Q: How much does liquid cooling cost compared to air cooling? Upfront, liquid cooling costs 30–80% more than equivalent air cooling infrastructure depending on architecture. At rack densities above 40 kW, the total cost of ownership over 5 years typically favors liquid cooling due to energy savings and higher compute density per square foot.
Q: Can existing air-cooled data centers be retrofitted for liquid cooling? Yes, but the complexity varies by architecture. RDHx is the easiest retrofit (weeks per row, no server changes). D2C requires server modifications and new plumbing (months). Full immersion requires significant facility changes (12–18 months for a meaningful deployment).
Q: What is the difference between single-phase and two-phase immersion cooling? Single-phase immersion keeps the dielectric fluid in liquid form throughout the cycle. Two-phase immersion uses a fluid that boils at chip surface temperatures, absorbs latent heat during phase change, then condenses and recirculates. Two-phase is more efficient but more complex and expensive.
Q: Who are the leading vendors for hyperscale liquid cooling in 2026? Key vendors include ASUS (server platforms), Vertiv and Schneider Electric (CDUs and facility infrastructure), Accelsius and GRC (two-phase immersion), and Auras Technology and Cooler Master (thermal components). NVIDIA’s Vera Rubin platform is driving significant ecosystem alignment [2].
Q: How does intelligent liquid cooling affect AI training performance? Intelligent cooling systems that manage thermal headroom dynamically can increase effective GPU utilization by 5–15% by preventing thermal throttling and enabling more aggressive clock speeds when cooling capacity allows [4].
Q: What is the payback period for liquid cooling investment? At rack densities of 40–60 kW, payback periods of 2–4 years are typical. At 80+ kW with two-phase immersion, payback can compress to 18–30 months because air cooling alternatives require significantly larger, less efficient facilities.
Q: Is liquid cooling relevant for edge AI deployments? Direct-to-chip cooling is beginning to appear in edge AI deployments for high-density inference hardware. Full immersion is generally impractical at the edge due to facility requirements, but RDHx and D2C are viable for edge data centers running GPU inference at 20+ kW per rack.
Conclusion: Actionable Next Steps for Data Center Operators
Liquid cooling breakthroughs beyond direct-to-chip are not a future consideration for hyperscale AI operators in 2026. They are a present operational requirement. With rack densities crossing 40 kW and GPU platforms designed for liquid cooling from the ground up, the question is no longer whether to adopt liquid cooling, but which architecture to deploy and how fast.
Actionable next steps:
Audit current and projected rack density. If any racks are approaching 25 kW or if AI workload growth will push them there within 18 months, begin liquid cooling planning now.
Run a pilot before committing at scale. Deploy D2C or immersion cooling across 5–10 racks for 60–90 days. Validate PUE, maintenance workflows, and DCIM integration before full rollout.
Model the ROI at your actual density. Use the framework above: current PUE vs. target PUE, energy cost savings, hardware lifespan extension, and density gains. The numbers change significantly between 20 kW and 60 kW rack profiles.
Engage vendors early on facility requirements. Chilled water capacity, secondary containment, and overhead clearance for immersion all require facility design input. Bring cooling vendors into the conversation before finalizing server procurement.
Plan for intelligent cooling integration. Budget time and resources for DCIM and orchestration layer integration. The efficiency gains from predictive maintenance and dynamic workload migration are significant but require proper integration to realize.
Monitor two-phase immersion developments. For operators planning deployments in 2027 and beyond, two-phase immersion with chip-embedded microfluidics is the direction the industry is heading. Greenfield facilities built today should be designed with immersion-compatible infrastructure even if D2C is the initial deployment.
The data center operators who move decisively on liquid cooling in 2026 will have a meaningful structural advantage in compute density, energy costs, and AI workload capacity over those who delay.
References
[1] AI Supercharges The Race – https://www.lombardodier.com/insights/2026/january/ai-supercharges-the-race.html
[2] ASUS Liquid Cooling Solutions AI HPC – https://press.asus.com/news/press-releases/asus-liquid-cooling-solutions-ai-hpc/
[3] Data Center Cooling Trends And Insights For 2026 – https://www.racksolutions.com/news/blog/data-center-cooling-trends-and-insights-for-2026/
[4] Liquid Cooling 2026 – https://www.bytebt.com/liquid-cooling-2026/
[5] 2026 Data Center Trends AI Cooling Power Insights – https://datacenterworld.com/article/2026-data-center-trends-ai-cooling-power-insights/
[6] Accelsius CEO on Two-Phase Cooling – https://www.youtube.com/watch?v=TZbao74qsZs
[7] NVIDIA GTC26 Session S82095 – https://www.nvidia.com/gtc/session-catalog/sessions/gtc26-s82095/
Note: The internal links provided in the source list are specific to Canadian mortgage topics and are not contextually relevant to this article on liquid cooling for hyperscale AI data centers. Including them would mislead readers and reduce content credibility. They have been omitted in accordance with the instruction to place links only where they add genuine value.